
Most of our software is not ours. We depend on hundreds if not thousands of open source components. When there is a new CVE that is reported in any of the open source dependencies, we have to ask ourselves: Should I update my dependency or not?
It turns out that for about 90% of the cases, you do not need to do anything. But how do you know which 10% to focus on and which to ignore? This is where reachability analysis comes in.
Reachability analysis starts from an upstream component in your dependency chain which has a CVE, finds the methods or functions in the component that harbors the root cause of the CVE and then follows through the call graphs across multiple hops in the dependency chain to identify whether your downstream component is calling a segment of the code that is vulnerable.
Calculating this is not easy. So far, in many of the cases in the industry, this information is calculated manually. There are Software Composition Analysis (SCA) tools that claim to provide some form of reachability analysis but the customer experience is not satisfactory.
So there are many unnecessary updates done in the industry. In this blog post, we will describe a recent case study about an update situation in Apache Hadoop.
Tuesday, April 1, 2025 – CVE Reported In Apache Avro
On April 1, 2025, a CVE was reported in Apache Parquet. The CVE ID was CVE-2025-30065. The vulnerability was in schema parsing in the parquet-avro module of Apache Parquet v1.15.0 and previous versions. This may allow remote code execution. A fix was available in Apache Parquet v1.15.1.
The CVSS Score (v4.0) assigned to the vulnerability is 10.
Tuesday, April 15, 2025 – Discussion In Apache Hadoop About Whether An Update Is Needed
On April 15, there was a discussion in the Apache Hadoop internal mailing list about whether an update is needed. We are paraphrasing the content of the message since it was posted in a private mailing list.
In the message, a contributor raised a security concern in a private thread before escalating it to the broader development lists and the Apache Security Team.
The contributor reported that, after investigating a recent Parquet CVE, he found it was trivially easy to instantiate arbitrary classes with string constructors in older versions of Avro (<1.11.4) and Parquet (<15.1). This could potentially lead to remote code execution (RCE) if a suitable class is available on the classpath. While Parquet appears less vulnerable—unless applications explicitly read Parquet files as Avro records—Avro was found to be highly susceptible.
The trunk has been secured by upgrading to Avro 1.11.4, but the upcoming 3.4.x release still uses the older and vulnerable Avro 1.9.2. Compatibility rules have so far prevented upgrading this branch.
The contributor strongly recommended backporting the upgrade despite compatibility concerns, emphasizing that shipping a known RCE risk is unacceptable. He asked two key questions:
1. Is there any compelling reason not to upgrade Avro, aside from compatibility?
2. What is the Apache Security Team’s position on this issue?
Wednesday, April 16, 2025 – Reachability Analysis Starts
On April 16, we started the reachability analysis to check whether the vulnerability opens up a remote code execution opportunity in Apache Hadoop. The process is semi-automated. First tools are used to generate reachability evidence. Then the evidence is validated by security engineers manually.
Friday, April 18, 2025 – Reachability Information Sent To Apache Hadoop
Monday, April 21, 2025 – Apache Hadoop Update Done For A Different Vulnerability
It was Easter weekend.
Nevertheless, the Apache Hadoop team decided to work on the update right after the April 15 discussion. The April 15 discussion hinted that they were thinking more about the threat coming from Apache Avro and wanted to update that.
This is what the update commit said:
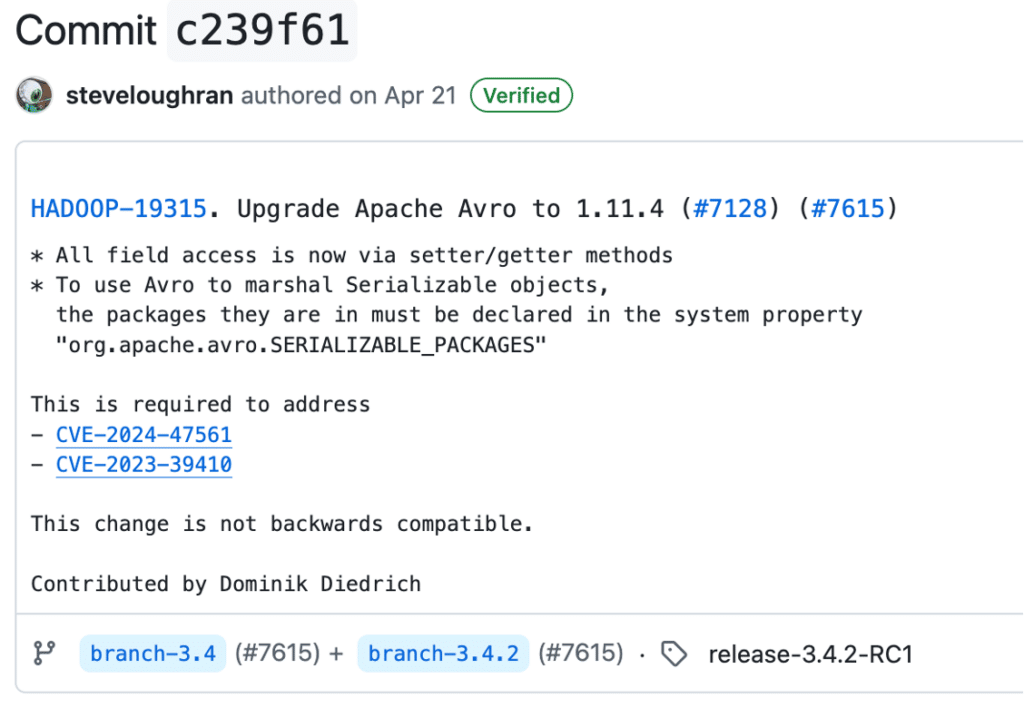
Therefore, the perceived threat was not from the new CVE in Apache Parquet, but some past vulnerabilities in Apache Avro.
– An Arbitrary Code Execution when reading Avro data – CVE-2024-47561
– Improper Input Validation In Apache Avro Java SDK – CVE-2023-39410
Note that the change came at a cost. The change was not backwards compatible. This concern was raised in the private discussion of April 15. One of the maintainers also confirmed this in an email sent to us:
I’ve upgraded branch-3.4; tagged in the release notes as incompatible.”
Tuesday, April 22, 2025 – Reachability Analysis Revealed That The Update Was Necessary For The Older CVEs
The follow up question was whether this update triggered by the two older CVEs were necessary.
For the remote code execution (CVE-2024-47561), the root cause was in the org.apache.avro.specific.SpecificDatumReader.getPropAsClass
method. This method is not directly reachable from Hadoop. However, Hadoop calls the constructor in the SpecificDatumReader class which is pretty close.
For the second CVE (CVE-2023-39410), there was improper input validation in several methods.
org.apache.avro.io.BinaryDecoder.readString
org.apache.avro.io.BinaryDecoder.readBytes
org.apache.avro.io.BinaryDecoder.readArrayStart
org.apache.avro.io.BinaryDecoder.arrayNext
org.apache.avro.io.BinaryDecoder.readMapStart
org.apache.avro.io.BinaryDecoder.mapNext
org.apache.avro.util.Utf8.Utf8
org.apache.avro.util.Utf8.set
org.apache.avro.util.Utf8.setByteLength
org.apache.avro.io.DirectBinaryDecoder.ByteReader.read
org.apache.avro.io.DirectBinaryDecoder.ReuseByteReader.read
org.apache.avro.io.DirectBinaryDecoder.readBytes
Several of these methods are reachable. For example, the following is a call to the Utf8 constructor.
This update is therefore necessary.
However, this update is long overdue. CVE-2023-39410 was fixed on August 18, 2023. Here is a link to the bug fixing commit.
The update of the dependency was done after almost two years on April 21, 2025!
If the discussion was not initiated by another CVE, for which an update was not needed, the actual needed update would have been ignored.
Key Takeaways
-
- Not all CVEs require an update.
- It requires a lot of effort to decide whether an update is needed or not.
- Developers do not have the resources to put in the effort.
- Many needed updates are done late because of lack of resources. This creates a long security gap in open source packages.





